강화학습을 pytorch로 구현하는 게 좋다는 말을 들었다.
사실 tensorflow든, pytorch든 기본적인 구조는 동일하기에
사투리 정도로 치부하는 사람이 있다.
하지만 일본어 자체를 모르면 오사카 사투리든, 도쿄 표준어든 외국어인 것은 마찬가지이므로
pytorch 튜토리얼을 차근차근 진행해보았다.
해당 튜토리얼은 pytorch 공식 사이트에서 제작해서는
60분짜리 튜토리얼이라고 대놓고 강조하고 있는데
실제로 해보니 정말 그렇다.
네 개의 미니 세션으로 이뤄져 있으며
각 세션은 구글 코랩과 연동되어 있어서 바로 바로 코드를 돌리며 확인할 수 있다.
코랩을 이용하면 GPU가 미약한 내 컴퓨터에서도
당당히 pytorch GPU 버전을 사용할 수 있다.
블로그를 주욱 읽어 내려가면 자연스럽게 이해할 수 있는 내용들인지라.
본 글에서는 중요한 개념만 다시 짚고 넘어가도록 해야겠다.
세션 1. What is PyTorch?
텐서의 개념만 챙겨가고, 나머지는 코드를 돌리면서 확인하면 끝이다.
텐서는 기본적으로 행렬과 동일하다고 보면 된다.
"그럼 행렬이라고 하지, 뭐하러 텐서라고 부르냐!" 하고 아우성치는 성급한 사람들도 있겠지만
GPU를 활용한 연산이 가능한 행렬을 텐서라고 부르는 듯 하다.
텐서를 검색하면 나오는 위키피디아 이미지인데,
이런 이미지에 전혀 겁먹을 필요가 없다는 것이다.
"텐서? 아, 행렬 말하는 거구나!" 하고 넘어가도 좋다.
세션2. Autograd: 미분 도우미
내가 딥러닝을 처음 공부했던 게 2018년도였을 것이다.
"밑바닥부터 시작하는 딥러닝"이라는 책으로 그룹스터디를 진행했는데
정말 지루하기 짝이 없는 시간이었다.
"어라? 내가 생각하던 알파고 같은 애들은 왜 안나오는 거야?"
하고 물을 때는 이미 강습료를 지불한 상태였다.
그래도 꾸역꾸역 딥러닝의 구조를 책으로 익혔고,
당연히 스터디 기간이 종료되자마자 머릿속에서 삭제되어 버렸다.
단 하나 남은 것이 있다면, 책의 '목차' 정도이다.
딥러닝을 위해서는 여러 레이어가 필요하고,
"학습"한다는 의미는 그 레이어를 왔다 갔다 하면서
파라미터를 업데이트 해주는 것입니다... 등등
이런 내용들이 드문 드문 기억나는 것이다.
pytorch는 그런 단편적인 기억만으로도 딥러닝을 구현할 수 있는 아주 고마운 장치다.
아니, 오히려 좋다. "아, 그런 게 있었지" 하며 넘어가면 되는데
나중에 누가 물어본다면 "구글에 '역전파법' 검색해봐" 따위의 말을
멋대로 지껄일 수 있기 때문이다.
세션 2에서 보여주는 것도 이와 마찬가지이다.
역전파법을 책으로 공부할 때는 정말 지루하기 짝이 없었는데
pytorch는 "이런 지루한 내용은 내가 해줄게" 하듯이 후루룩 넘어가주는 것이다.
다만 몇 가지 기술적인 부분은 익혀둬야 한다.
requires_grad=True를 설정함으로써 역전파 확인용 트래킹 장치를 사용하는 것과
역전파를 시작할 때는 .backward()함수로 선언하고 들어가는 것 정도가 그렇다.
x = torch.ones(2, 2, requires_grad=True)
out.backward()위와 같은 식이다.
세션3. Neural Network
여기는 실제로 인공신경망을 구현하는 부분이라 모르는 것 투성이었다.
우선 CNN의 기본적인 구조부터 알고 있어야 한다.
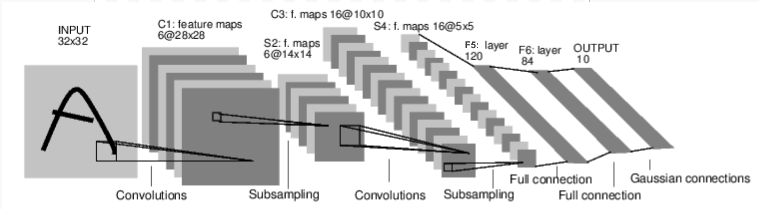
CNN은 하나의 인풋 이미지(사이즈는 32 pixel x 32 pixel)가 있을 때
일련의 과정을 통해 여러 카테고리 중에서 해당하는 것을 골라주는 블랙박스같은 존재이다.
말이 블랙박스지, 그 안은 위와 같이 구성되어 있다.
인풋 이미지가 알파벳 A로 설정되어 있지만,
Output 개수가 10개이기 때문에 0~9까지의 정수 중 하나라고 생각하는 게 낫다.
자, 그럼 인풋 이미지가 있다고 해보자.
그 다음은 Convolution Layer이다.
구체적인 내용은 이 블로그에 잘 설명되어 있으므로 형식만 눈여겨 보자면,
6개의 (5, 5) 사이즈 kernel을 사용해서 (32 x 32) 인풋을 훑어내려가고
결과물은 6개의 사이즈=(28, 28) 채널이 탄생한다.
여기서 채널이란, 위 사진에서 보이는 네모 하나 하나를 말한다.
Subsampling은 위의 Convolution layer에서 나온 (6, 28, 28) 결과물을
(6, 14, 14)로 축소시켜준다.
두 번째 Convolution Layer는 16개의 5x5 kernel을 이용해서
(16, 10, 10)의 결과물을 만들고
마찬가지로 두 번째 subsampling layer에서는 (16, 5, 5)로 축소한다.
별도 함수(num_flat_features)와 view 함수를 이용해서 (16, 5, 5)의 결과물을
(1, 16*5*5)로 한 줄로 쫙 펴준 뒤에 만나는 것이 Fully Connected Layer인데,
16*5*5 = 400개의 파라미터를 120개의 결과물과 연결해주는 첫 번째 FC layer,
120개를 84개와 연결하는 두 번째 FC layer,
84개를 최종적으로 10개의 카테고리로 연결해주는 세 번째 layer가 존재한다.
이렇게 풀어서 CNN을 살펴보니 참 간단하다.
인간의 지각 능력이라는 것도 고작 이렇게 연결된 것과 별로 다름이 없다니
신기하기도 하고, 뭔가 씁쓸한 기운이 들지만
아직 인간 지능을 온전히 따라잡기는 멀었다(이런 단순한 분류 실력은 이미 기계가 뛰어넘었지만).
세션4. Real Life Example
실제로 온전한 CNN 분류기를 만들어보는 시간이다.
CIFAR-10이라는 데이터셋을 이용하는데,
주어진 이미지를 열 개의 카테고리로 분류하는 작업이다.
데이터셋을 두 번 왕복하면서 학습을 하도록 코드를 조금 수정한 후에
위에서 진행했던 구조를 그대로 사용해서 학습을 한 결과는 아래와 같다.
Accuracy of the network on the 10000 test images: 53 %
10개 중에 무작위로 하나를 찍은 10%의 확률보다 무려 다섯 배가 늘었다.
레이어 수를 늘리거나 하는 방식으로 좀 더 복잡한 구조를 사용하게 된다면
성공률은 더욱 늘어날 것이다.
최적의 레이어 수, kernel 사이즈 등에 관한 논문도 익히 진행되었던 것으로 기억하는데
실행단에 위치한 공학자로서는 최적으로 판명난 것을 사용하기만 하면 그만이다.
그래도 이유는 알고 있어야 현명하다는 소리를 들으니
이 블로그를 참고하면 된다.
'트렌드 한눈에 보기 > 학계 트렌드' 카테고리의 다른 글
| 탐조 입문자를 위한 딥러닝 활용기 - 1편 (0) | 2021.01.25 |
|---|---|
| 한국 정부에서 1600억을 들여 개발 중인 아이언맨 슈트 (0) | 2021.01.19 |
| [CS234] Lecture 16: Monte Carlo Tree Search 정리 (0) | 2021.01.14 |
| [CS234] Lecture 15: Batch RL 정리 (0) | 2021.01.08 |
| [CS234] Lecture 13: Fast Learning III 정리 (2) (0) | 2021.01.07 |



