14강은 Chelsea Finn 교수의 Meta-Learning 강좌였고
15강은 Batch Reinforcement Learning의 차례이다.
사실 CS231n강좌를 들을 때에도
Batch Normalization은 욕하면서 넘겼기에(이해가 안된다 퉤퉤)
오히려 Meta-Learning 강의를 듣고 싶었는데,
아쉽게도 해당 영상은 유튜브에 업로드 되지를 않았다.
근데 이참에 batch류에 대해 이해할 수 있다고 생각하니, 오히려 좋아.
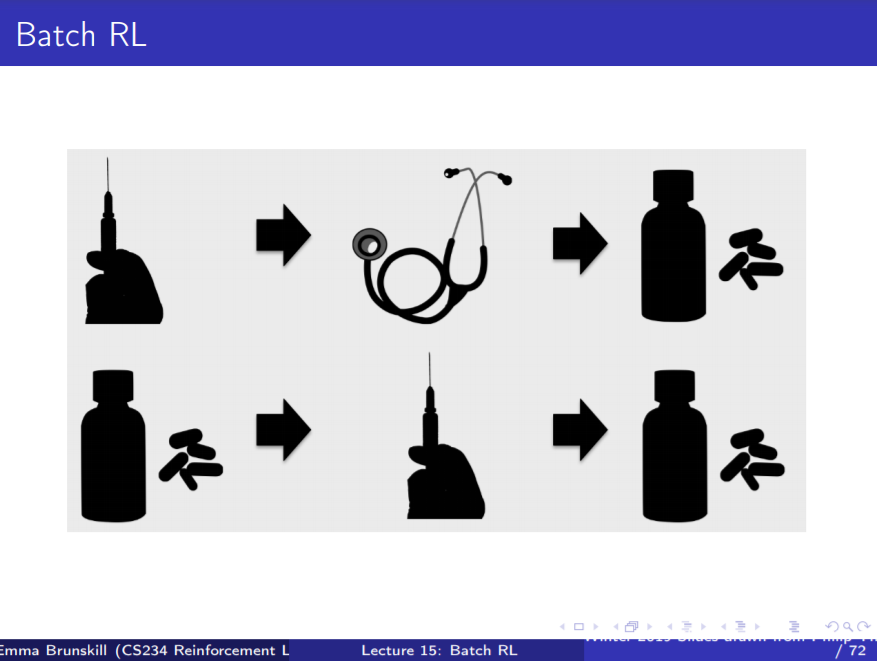
Batch RL이 상정하는 문제는 다음과 같다.
치료 과정의 경우, 주사를 맞고 약을 먹는 것과
약을 먹고 주사를 맞는 경우에 회복률 차이가 존재하는지?
그 차이를 정확히 감별하기 위해 필요한 정보는 무엇인지?
일반화해서 말하자면, 기존 프로세스가 있을 때
순서를 바꿈으로써 성능 개선의 여지가 있는지에 대한 연구가 되겠다.

오늘 배울 내용은 어떻게 하면 "안전하게"
강화학습 프로세스를 구성할지에 대한 내용이다.
"안전 놀이터" 같은 느낌이 드는 것은 어쩔 수 없지만,
풀어서 이야기하자면 기존의 행동지침(Policy)이 있을 때
새로운 행동지침이 성능을 개선할 수 있음을 보장하는 것이다.
"뭐야, 그간 해왔던 Monotonic Improvement나
e-greedy, UCB, Thompson Sampling이랑 똑같은 거 아냐?" 하는 사람도 있겠지만
똑같은 내용이면 뭐하자고 이름까지 "Batch RL"이라고 했겠습니까,
그냥 Fast RL IV 라고 부르고 말지.
좀 더 지켜보도록 하자... 뭐가 다르지?

일단 Batch RL을 배우기 위한 표기법부터 확인해보자면,
Policy, Trajectory, Historical Data는 그대로이다.
그런데 Historical Data from Behavior Policy, $\pi_b$가 추가되었다.
이는 말하자면, 특정 행동지침에서 추출해낸 과거 데이터라고 할 수 있다.
예컨대, 의사의 진료 방침에 따른 데이터 정도가 될 수 있다.
하지만 현실세계에서 인간이 만들어내는 데이터셋은
그렇게 엄밀하게 분류되어 있지 않으므로 진료 데이터 예시는 적절치 못하고,
인터넷 광고 배너 클릭율 등 기록이 잘 되어 있는 경우에 적용 가능하겠다.

새로 만들어낸 행동지침과 기존 행동지침을 비교하려면,
우선 행동지침을 평가하는 방법부터 알아야하는데, 구체적인 방법은 위와 같다.
사실 그간 배워왔던 Policy Evaluation 방법들을 조금씩 변형한 것에 지나지 않아서
크게 의미가 없는 것 같기도 하다.

먼저 OPE는 단순히 행동지침의 value를 계산하는 알고리즘이다.
기존 행동지침도 넣어보고, 새로운 행동지침도 넣어본 뒤에
두 개의 결과값을 서로 비교하는 식이다.
당연히 비효율적일 것 같은데,
굳이 이름까지 붙여가면서 설명해 줄 필요가 있나하는 심술이 든다.

방법도 몬테카를로이다. 으휴 뻔해.
몬테카를로는 쉽게 생각하면 Trajectory의 평균같은 존재라 분산이 엄청나게 크다.
그래서 강의 중반부는 대부분 분산을 줄여주기 위한
"Importance Sampling"에 대한 내용이다.
나는 굳이 이해하지 않고, 그런 것이 있구나- 하는 정도로 넘어가기로 했다.
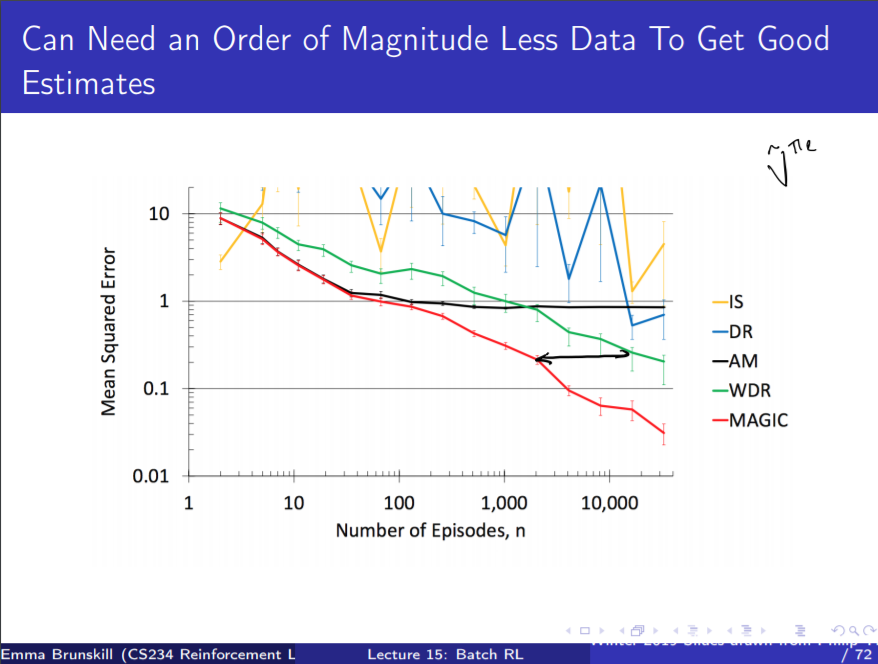
성능은 꽤 잘 나오는 편이다.
몬테카를로라고 우습게 보면 안되겠는걸...? 하는 생각이 들지만
어디까지나 몬테카를로일 뿐이다.
몬테카를로를 설명하고 난 뒤, HCOPE와 SPI를 설명해야 하는데
웬걸, 그냥 후루룩 훑어내고 끝났다.
분명히 Batch Reinforcement Learning은
기존에 배웠던 Policy Evaluation 방식과 별 다른 게 없을 테다.
시간 낭비했다고 투덜대지 말고,
CNN과 RL에서의 Batch류에 대해 "그냥 넘어가도 되는 부분" 임을
귀납적으로 추론해내는 시간이었다고 생각하도록 하자.
'트렌드 한눈에 보기 > 학계 트렌드' 카테고리의 다른 글
| PyTorch 튜토리얼, 60분 내로 끝낼 수 있을까? (0) | 2021.01.18 |
|---|---|
| [CS234] Lecture 16: Monte Carlo Tree Search 정리 (0) | 2021.01.14 |
| [CS234] Lecture 13: Fast Learning III 정리 (2) (0) | 2021.01.07 |
| [CS234] Lecture 13: Fast Learning III 정리 (1) (0) | 2021.01.05 |
| [CS234] Lecture 12: Fast Learning II 정리 (0) | 2021.01.04 |



