
CS234 대망의 마지막 강의를 장식하는 주제는 Monte Carlo Tree Search[MCTS]이다.
몬테카를로는 익히 배웠던 비효율적인 방식인데다가
Tree Search라고 하면 가지치기로 결정을 내리는 이미지가 있어서 그런지
그동안 배웠던 멋진 Policy Gradient 따위의 알고리즘을 제치고
마지막 강의로 쓸 법한 내용이 맞긴 한가 하는 의문이 든다.
하지만 MCTS는 생각보다 굉장히 중요한 알고리즘이라고 한다.
알파고에 적용되어 있을 뿐만 아니라,
모델이 주어진 경우의 강화학습에 대한 이해를 높여준다나.
일단 알파고가 나온지도 5년이 지났는데(군대에 있었다),
아직도 알파고 하면 멋져보인다는 것은 나름대로 문제가 있다.
또한 모델이 주어진 경우의 강화학습은 왜 이렇게 많이 나오는 건지 모르겠다.
실생활에 적용하기 위해서는,
어쨌든 모델이 없는 경우를 중점적으로 공부해야 하는 것 아닌가?

하지만 이번 강의에서는 모델의 상태전환확률 매트릭스(T),
또는 보상 함수를 배우는 방법을 가르친다고 하니,
실생활에도 어느 정도 사용이 가능하겠군 싶다.
또한 알파고에서 어떤 역할로 쓰였는지도 대충 짐작이 간다.
바둑에서 보상을 설정하고 확률을 계산하는 데 쓰였겠지?
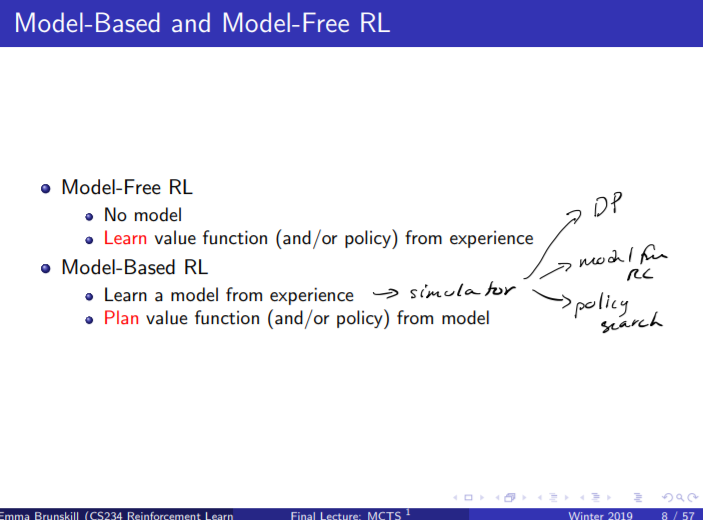
더 기똥찬 것은 Model Based RL을 통해 모델을 학습한 뒤
그것을 시뮬레이터로 사용할 수 있다는 것이다.
그 안에서 모델을 모르는 척
Model free RL을 쓰든, Dynamic Programming을 쓰든 자유다.
생각보다 MCTS의 효용이 높은 것 같다.
그러고보니, 실생활에서 쓰지 못하는 학습 알고리즘은 모델 기반 강화학습이 아니라
"모델이 주어진 경우" 였던 것 같기도 하고....
여튼 미안하다 MCTS!
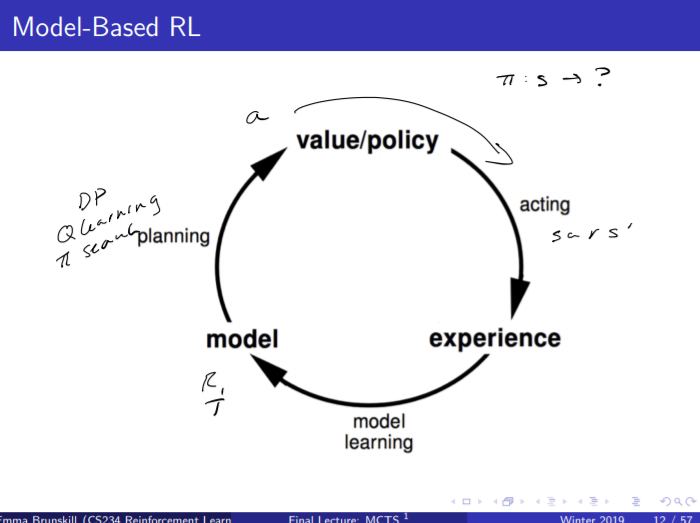
학습 구조는 위와 같다.
초기에 주어진 (s, a, r, s') tuple이 있으면
그로부터 R, T를 계산해서는 다음 행동 a을 내놓는다.
MCTS와 함께라면 명확한 value나 policy를 계산할 필요도 없다고 하는데
보나마나 상당한 노가다를 컴퓨터로 돌리게 하는 식일 것이다.
편리하긴 하지만 뭐 거기까지인 것이다.

모델기반 강화학습의 장단점은 명확하다.
빠르게(최근에는 더 빠른 알고리즘이 많아졌겠지만) 학습이 가능하지만
오차가 누적되므로 정확성은 장담하지 못한다.
그리고 또 하나의 장점은 일단 모델을 배워두면
보상함수 등에 변화가 생기더라도 빠르게 적응이 가능하다는 것이다.
예를 들면 방에서 나가는 길을 알고 있을 때(모델을 알고 있을 때)
"저쪽 문은 막혔으니 이쪽 문으로 나가" 하는 보상함수가 갑작스레 주어져도
"그렇게 하겠습니다" 하고 냉큼 다른 쪽 문으로 퇴근할 수 있다는 것이 될까나.

위 슬라이드는 "모델을 학습한다"라는 말의 뜻을 설명한다.
모델이란 우선, <S, A, P, R> 로 이뤄진 조합이고
과거 경험 데이터셋 ${S_1, A_1, R_2, S_2, ...}$이 있을 때
${S_i, A_i}$에서 ${R_i' S_i'}$를 추출해낼 수 있는 블랙박스를 만드는 것이
모델을 학습하는 과정이라고 할 수 있다.

이 때, 모델을 학습해 놓은 상태라면
기존 경험 ${S_i, A_i}$만 사용할 것이 아니라
만들어낸 모델, 즉 시뮬레이터를 통해 $S_i'$를 새로 만들어 낼 수도 있다.
기존 경험이 있는데 굳이 새로운 경험을 가상으로 만들어낼 필요가 있냐 묻는다면
예전의 그 구닥다리 A, B 모델을 통해 확인해볼 수 있다.
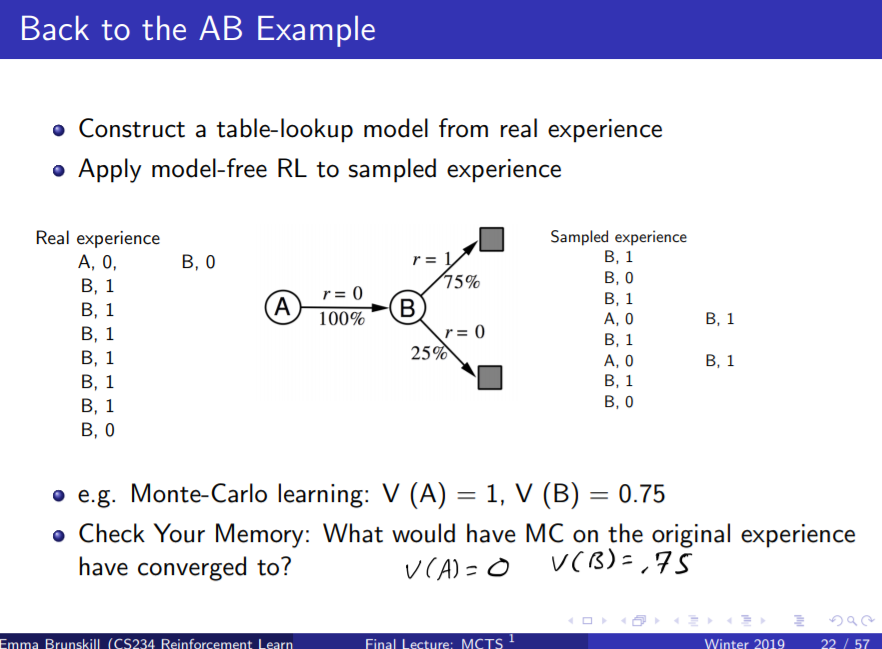
Monte Carlo와 TD-Learning을 배울 때 썼던 그 예제이다.
왼쪽이 실제 경험이고 가운데 다이어그램이 모델이다.
오른쪽은 모델을 통해 임의로 만들어 낼 수 있는 조합이다.
몬테카를로를 통해서는 V(A) = 0, V(B) = 0.75라는 값을 구했는데
새로운 가상의 경험을 만들어내서는 몬테카를로를 돌리면
전혀 다른 값을 구할 수 있다.
그런 식으로 데이터를 확보해서는 참값에 더 나아갈 수 있다.

하지만 기껏 만들어낸 모델이 잘못되어 있는 경우가 있다.
아마 잘못된 경우가 대부분이지 않을까 싶다.
그런 경우에 방안은 물론 모델은 폐기한 채
실제 경험을 바탕으로 Model-Free RL을 사용하는 것이다.
사실 너무 당연한 말이라서 굳이 이 슬라이드를 왜 넣었는지 의문이다.
마지막 강의라고 너무 대충 넘어가는 거 아냐?

의문만을 남긴채 넘어간 다음 슬라이드는 시뮬레이션 기반 탐색기법이다.
오호, 이것이야말로 알파고에 쓰였던 알고리즘이 틀림없다.
알파고 소개영상에 늘 나오는, 끝없이 뻗어나가는 시뮬레이션 그림이
바로 이 알고리즘이 아닐까 하는 기대감을 품게한다.


알고리즘을 살짝 읽어보면, 얼추 비슷한 것 같기도 하다.
시뮬레이션 지침 $\pi$가 있을 때,
현재 상태에서 K개의 에피소드를 시뮬레이션한 후
해당 행동들의 가치를 몬테카를로 기법을 통해 평가해서는
최적의 행동을 뽑아내는 것이다.

결국 강의 초반부터 호들갑을 떨면서 시작했던 MCTS의 정체가 이것이다.
사실 생각해보면 일반적으로 바둑이나 체스기사 들의 머릿속을 상상한 것과 동일하다.
문제는, 경우의 수가 그렇게 많은데
어떻게 최적의 행동을 바로바로 찾아낼 수 있느냐는 것이다.

MCTS에서 사용했던 방법은 Upper Condition Boundary를 사용하는 것이다.
UCB는 최적의 행동을 찾는 과정에서
기존에 사용하던 행동지침과 랜덤한 행동 중에서 어떤 것에 비중을 둘 지
선택하는 방법이었고, 꽤나 안정적인 성공률을 보장하는 기법이다.
"이걸로 가능하다고?" 하고 생각할 수도 있다.
알파고와 이세돌이 붙기 직전까지도 많은 사람들이 그렇게 생각했다.
하지만 결국 그걸로도 가능하다는 것이 밝혀지고 말았다.

그렇게 CS234가 끝이 났다.
강좌 초반에 설정했던 목표를 살펴보자.
1. 강화학습과 다른 AI의 차이점은 무엇인가?
- 강화학습에서의 Agent는 스스로 데이터를 만들어내고 학습한 뒤
이를 바탕으로 결정을 내릴 수 있다.
2. 실생활 문제가 주어졌을 때, 강화학습을 적용가능한지 판별할 수 있는가?
- 아니오...
3. 강화학습 알고리즘을 코드로 구현할 수 있는가?
- 아니오.....
나머지는 가슴아프니 패스하기로 하자.
결국 실행과는 거리가 먼 반쪽짜리 수강이 되었지만, 첫술에 배부르랴.
앞으로 다양한 코드들을 접하면서 실행해 나가면 될 일이다.
'트렌드 한눈에 보기 > 학계 트렌드' 카테고리의 다른 글
| 한국 정부에서 1600억을 들여 개발 중인 아이언맨 슈트 (0) | 2021.01.19 |
|---|---|
| PyTorch 튜토리얼, 60분 내로 끝낼 수 있을까? (0) | 2021.01.18 |
| [CS234] Lecture 15: Batch RL 정리 (0) | 2021.01.08 |
| [CS234] Lecture 13: Fast Learning III 정리 (2) (0) | 2021.01.07 |
| [CS234] Lecture 13: Fast Learning III 정리 (1) (0) | 2021.01.05 |



