인터넷에 검색해보면, CNN과 LSTM 튜토리얼은 잔뜩 나온다. 하지만, 죄다 기존의 데이터셋을 활용해서 진행하는 튜토리얼들이다. CNN과 LSTM을 쓸 줄 알게 된다는 점에서 그런 튜토리얼들이 나쁜 것은 아니지만, 결국 실제 사용해보기 위해서는 데이터셋을 구축하는 방법부터 진행해야 한다.
시계열 예측 | TensorFlow Core: 기존 데이터셋을 활용하는 튜토리얼
시계열 예측 | TensorFlow Core
시계열 예측 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 튜토리얼에서는 TensorFlow를 사용한 시계열 예측을 소개합니다. Convolutional/Recurrent Neural Network(C
www.tensorflow.org

custom dataset을 활용하기 위해서는, 우선 예시 데이터셋이 어떻게 사용되는지부터 알아야 하는데, 튜토리얼 상에서 이를 파악하기란 쉬운 일이 아니다. 의지만 있다면 할 수 있겠지만, LSTM과 CNN을 익히는 것만 해도 벅찬 상황에서 데이터셋 형성 방법까지 알아야 해? 하는 식으로 의지가 약해지기 마련이다. 위 튜토리얼에서는 데이터셋을 나름의 방법으로 정리해 놨는데, 이를 잘 읽어보면 데이터셋의 형성 방법을 알 수 있을지도 모른다. 하지만 난 떠먹여주는 방식을 원한 것이다.

결국 이것 저것 삽질을 하다가 데이터셋을 만드는 방법을 나름대로 터득은 했다만, 생각해보면 위 튜토리얼을 차근차근 읽었더라면 더 빨랐을 수도 있다. 어쨌는 내 방식을 위 코드로 시작한다. walk, stair up, stair down 세 가지 모션을 motor encoder (각도, 각속도)와 IMU (가속도)로 수집했고, 각 데이터를 서로 다른 폴더에 담아두었다. encoder와 IMU는 20Hz로 작동하기에 20x3 행렬을 만들게 된다.
input_data numpy array에는 walk, stair up, stair down이 각 50개 씩 담겨있다. 그래서 150개의 모음이 되는 것이다.
test_Data numpy array는 마찬가지로 각 20개 씩 담겨있다. 그래서 총 60개의 모음이 된다.

input_data를 각 50개씩, test_data를 각 20개씩 담아준다.

그리고 이 부분. 놓치고 가기 쉬운 부분인데, 값들의 normalization이 필요하다. 꼭 각 행의 크기가 1일 필요는 없다. 내 데이터셋의 경우 가속도가 0.01m/s^2 단위로 설정되어 있어 유달리 큰 값을 가지는데, 이대로 학습을 시켰더니 가속도값에 지나치게 의존하게 되면서 성능이 잘 나오지 않았다. 각도의 경우 180을 넘지 않고, 각속도 역시 500 degree per second, 가속도는 1000 * 0.01m/s^2를 기준으로 normalization을 진행했다.

output data를 만들 때도 주의해야 한다. walk를 0, stair up 을 1, stair down을 2로 놓고 학습을 진행하려고 했는데, 이런 방식으로 되는 게 아니었다. one hot encoding이라는 방식으로 각 분류에 해당하는 행렬 위치를 0과 1로 이뤄진 값으로 표현해야 한다.

사용한 모델은 꽤나 간단하다. 283개의 parameter만 쓰일 정도면 deep learning이라고 부르기도 애매한 숫자다. 하지만 rule base로 코딩하기에는 또 꽤나 귀찮은 작업이 아닐수가 없을테다.

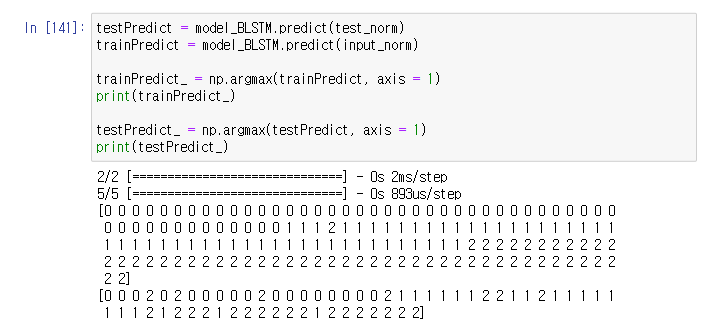
그럼에도 불구하고, 성능이 꽤 정확하다. 141번 코드에서 train dataset에서 결과가 상당히 좋은 것을 볼 수 있다. test dataset은 train보다는 약간 떨어지지만, 그래도 준수하다. 전반적으로 walk와 stair down을 헷갈려하고, stair down과 stair up을 혼동하는 모습을 볼 수 있는데, 직관적이진 않다. walk 데이터를 stair down과 헷갈릴 것이라면, stair down 데이터를 walk 와 헷갈려야 정상 아닌가?
모델링을 통해 움직임을 이해하는 활동을 얕게 나마 배운 입장으로서는 deep learning을 사용하는 것이 영 께름칙하다. 왜 이런 결과를 받는지도 모르는 채로, 무작정 딥러닝이 말하는 것을 받아다가 쓸 수 있는 것일까- 하는 의구심이 떨어지질 않는다. 부디 나같은 무지렁이들도 잘 이해할 수 있도록 explainable AI가 발전하기를 희망할 뿐이다.


