RNN (Recurrent Neural Network)이란, 아래 하나의 그림으로 표현이 가능하다.

recurrent 라는 말이 의미하듯 (재현하다, 재발하다), 연속적인 데이터가 들어올 때, 동일한 블록을 거쳐서 연속적인 Output을 내놓는 형태의 Neural Network라고 할 수 있겠다. 연속적인 Output의 대표적인 예시가 언어의 문장 구조이기에 번역 등의 업무에 많이 쓰이지만, 이미지 해석 등의 영역에도 충분히 쓰일 수 있다.
하지만 단순한 RNN 블록으로는 한계가 있었는데, 바로 문장이 길어질수록 초반에 들어온 정보를 잘 기억하지 못한다는 것이다. 이런 현상이 나타나는 이유는 Gradient Vanishing 문제와 연관이 있다고 하는데, 상세한 내용은 아래 논문(링크)을 참고하면 좋을 듯 하다(난 안할 거다).

LSTM이 이를 해결한 방법은, Gradient를 계산하는 방식을 다각화한 것이다. 구체적으로는 총 세 가지 방법을 적용해서 하나의 블록을 구성했고, 이를 통해 블록이 쌓일 수록 gradient가 희석되는 일을 방지했다고 한다. 쉽게 생각해보더라도, sequential한 데이터가 주어졌을 때, 하나의 데이터와 그 다음 데이터를 보며 1) 어떤 요소를 무시할 것인지 2) 어떤 요소를 중요하게 생각할 것인지를 고려할 것이다. 세 가지 방법 중 두 가지가 이에 해당하며, 마지막은 이 두 가지를 어떻게 취합할 것인지에 대한 내용이다.

1) 어떤 요소를 무시할 것인지: Forget Gate
2) 어떤 요소를 중요하게 생각할 것인지: Input Gate
3) 어떻게 위 두개를 취합할 것인지: Output Gate
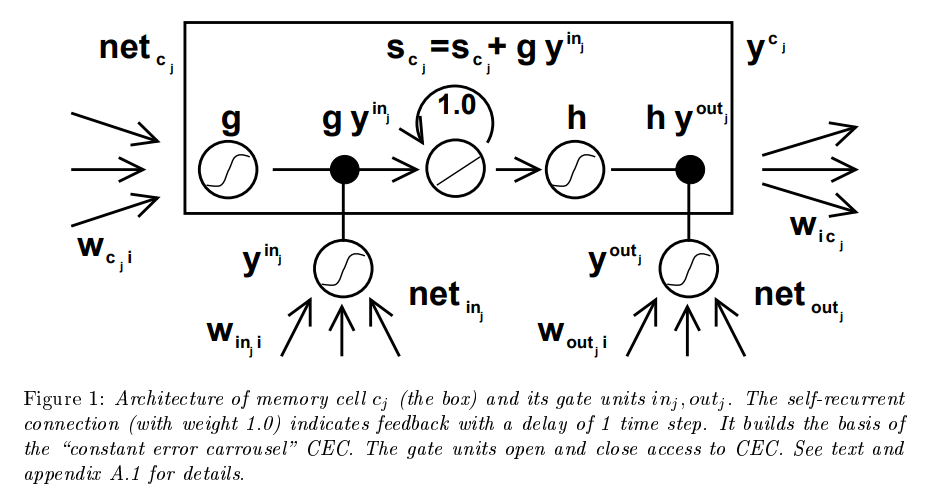
위 내용이 끝이다. 1997년 정도에 발표한 논문이라면 이 이상 복잡한 네트워크를 구성할 여력도 없을 것이다. LSTM을 제안한 첫 번째 논문을 확인해본다면 좋겠지만, 아쉽게도 위 그림만큼 친절하지 않다. 아래 그림은 원본 논문에 참고된 그림이다. 이런 그림을 가지고 위 같이 깔끔한 블록을 만들어냈다는 것이 신기할 따름이다.
LSTM을 pytorch로 구현해보는 정도로 LSTM 공부를 마치고, 바로 Transformer 로 넘어가도 되지 않을까 싶다. 그 이후에는 ChatGPT 등 보다 신기술을 공부해보는 시간을 처음으로 가져봐도 재밌지 않을까... 지금으로서는 기대해본다.
'트렌드 한눈에 보기 > 학계 트렌드' 카테고리의 다른 글
| MIT, Harry Asada, "Identification Estimation and Learning" 강의 정리 1: Least Squares (0) | 2023.05.20 |
|---|---|
| RoNIN: Robust Neural Inertial Navigation, IMU 사용기 (0) | 2023.03.14 |
| [딥러닝 공부] 2일차: Transformer를 공부하기 전에 훑어보는 LSTM (준비편) (0) | 2023.01.01 |
| [딥러닝 공부] 1일차: ResNet (2016)을 공부하는 2022년의 나 (실습편) (0) | 2022.12.25 |
| [딥러닝 공부] 1일차: ResNet (2016)을 공부하는 2022년의 나 (이론편) (0) | 2022.12.17 |



