Soft Actor Critic은 2018년 발표된 알고리즘인데,
Actor Critic 계에서는 아직도 최정상급 최적화를 자랑하고 있다.
그래서 이 알고리즘을 마지막으로 OpenAI Cartpole 예제를 마무리하려고 했는데,
그것이 화근이었다.
기존의 DDPG(지난 포스팅) 알고리즘은 Deterministic Policy Gradient를 사용하고 있으며
이는 주어진 상황에 행동을 매치시킬 때, 확률로 표현되지 않는다는 것을 의미한다.
예를 들어 A라는 상황에는 왼쪽, B라는 상황에는 오른쪽이 매칭되고
A 상황에 적합한 행동이 왼쪽일 확률이 80%, 오른쪽일 확률이 20% 같은 방식으로는
작동하지 않는 것이다.
하지만 실생활의 많은 부분에서는 그렇게 상황과 행동이 딱 들어맞는 경우가 없기에
초기 파라미터를 어떻게 설정해주느냐에 따라 학습 결과가 크게 요동치는 사례가 많았고,
Soft Actor Critic은 확률적으로 표현되는 상황에서도 적용할 수 있는
강화학습을 표방하며 나온 알고리즘인 것이다.
하지만 OpenAI Cartpole 는 애초에 확률적으로 만들어진 모델이 아닌 것 같다.
아무리 인터넷 자료를 뒤져봐도 openAI cartpole 예제를
soft actor critic으로 풀었다는 예시가 없어서(내가 이해할 수 있는 범주 내에서는)
상당히 오랜 시간을 내다 버리게 되었다.
결국 openAI가 아니라 pybullet이라는 학습 환경을 사용하게 되었고
이미지 렌더링 또한 좀 후지게 나오게 되었다.
학습 속도는 SAC가 DDPG에 비해 월등히 빠르다는 것이 실감나지만,
환경이 다르다보니 직접적인 비교가 가능한지 아직 확실치 않다.

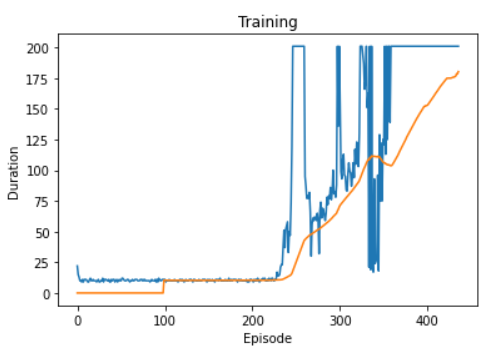
그래프에서 알 수 있듯이, 에피소드 100회차에
이미 duration(카트가 넘어지지 않고 버틴 시간) 200을 달성했으며
1000정도는 actor critic의 학습이 시작되기도 전에 가뿐히 뛰어넘었다.
결과는 아래와 같다.
렌더링이 좀 더 이뻤으면 좋았을걸...
'트렌드 한눈에 보기 > 학계 트렌드' 카테고리의 다른 글
| 탐조 입문자를 위한 딥러닝 활용기 - 2편 (0) | 2021.02.09 |
|---|---|
| PyTorch를 활용한 Soft Actor Critic - 2탄 (0) | 2021.02.08 |
| PyTorch를 활용한 Actor-Critic Tutorial 3탄 (0) | 2021.02.03 |
| PyTorch를 활용한 Actor-Critic Tutorial 2탄 (0) | 2021.02.01 |
| PyTorch를 활용한 Actor-Critic Tutorial 1탄 (0) | 2021.01.30 |



