지난 글에서 강화학습을 통해 코로나 시대에 가장 적합한 사회적 거리두기 정책을 선정하는 논문을 소개한 바 있다(링크). Sony AI에서 낸 논문인데다가, 아예 자체적으로 시뮬레이터를 만들어서 학습시킨 만큼, 우후죽순으로 나오는 딥러닝 논문 중 하나라고 하기에는 꽤나 신빙성 있는 자료라고 할 수 있다.
해당 논문 이외에도, 다양한 방식으로 사회적 거리두기 방안을 설정하는 논문이 꽤나 많이 나왔다. 그런 논문들의 공통점은 바로, "닥치고 3단계" 라는 것이다. 최대한 빨리 거리두기 단계를 높이고 확진자 수를 초기에 관리하는 것이, 전염병의 피해를 최소화시키는 방안이었다.
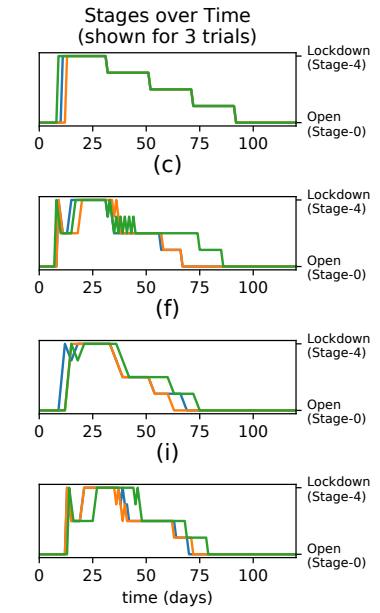
하지만 현실에서는, 거리두기를 강화하는 모습이 저것과는 영 다르다. 오히려 거리두기 기준을 세워놓고도, 모든 조건을 충족시켰음에도 강화를 계속해서 미루는 모습이 더 친숙하다. 이유는 사회-경제적 비용 때문이다. 거리두기가 강화되면 상권의 수입은 곤두박칠치지만, 확진자 수 조절은 그렇게 바로 효과가 나타나지 않는다. 최악의 경우 상권만 죽이면서 전염병 전파는 막지 못하는 사태가 벌어질 수도 있다. 그렇기에 정부에서는 소극적으로 대응할 수 밖에 없는 것이다. 가만히 있으면 중간이라도 가는 것일까나?
사실 이렇게 실제 사회를 제대로 반영하지 못하는 강화학습을 비롯한 딥러닝의 문제점은, 해당 논문에서만 발견되는 것이 아니다. 주식시장을 예측하는 논문 등 많은 데이터를 기반으로 실제 현상에 딥러닝을 적용했을 때 자연스럽게 나온다. 그만큼 실제 사회 현상들은 생각보다도 큰 변동성을 가지고 있다고 할 수 있다. 그런 의미에서 사회 현상에 대한 이상적인 해결책을 강구하는 것보다 먼저 수행되어야 할 것은, 사회 현상에 대한 이해라고 할 수 있다.

위 식이 앞서 소개한 논문에서 정의한 보상 함수이다. 보상함수란, 정책을 세웠을 때 (ex: 거리두기 단계 상향 / 유지 / 하향) 어떤 효과를 받을 수 있는지를 정량화한 것이다. 식 자체는 꽤나 복잡해보이지만, 크게 두 틀에서 분석할 수 있다. 우변의 왼쪽 항은 전염병으로 인한 중증환자 수를 줄이겠다는 것이고, 오른쪽 항은 거리두기 단계를 최대한 낮게 유지하는 쪽으로 정책을 결정하겠다는 뜻이다. 거리두기 단계를 낮게 유지하는 이유는, 사회-경제적 비용을 최소화하겠다는 뜻으로 해석할 수 있다.
정책에 대한 평가를 내려야 하는 보상함수에서, 아예 정책 결정을 유도한다는 것은 잘 이해가 가지 않는다. 하지만, 그만큼 사회-경제적 비용을 모델링하기가 어렵다는 뜻이다. 결과적으로 학습된 정책(그림 1)은 사회현상을 제대로 반영하지 못하게 되었다고 할 수 있겠다.
이 논문을 바탕으로 했을 때, 실제 사회현상을 반영하기 위해서는 보상함수를 수정할 필요가 있다. 어떤 식으로 수정해야 할까? 바로 현재 사회의 사회적 거리두기 정책을 "이상적"이라고 보는 것이다. 경제비용을 모델링한 오른쪽 항에 계수를 하나 둔 뒤에, 값을 조금씩 변화시켜가면서 추이를 확인할 수 있다. 실제 사회적 거리두기 정책을 시뮬레이션에 걸맞게끔 수정한 뒤에, 어떤 계수가 해당 정책 하에서의 보상함수를 가장 크게 만드는지 확인하면 된다. 수식으로 쓰자면 아래와 같겠다.

위 내용은 학내 코로나19 학생논문 공모전에 제출할 내용인데, 아무리 봐도 가만히 있으면 글을 쓰게 될 것 같지 않아서 이렇게 초안을 블로그로 남겼다. 별 문제는 되지 않겠지만, 문제가 되더라도 크게 상관은 없다.

'트렌드 한눈에 보기 > 학계 트렌드' 카테고리의 다른 글
| 강화학습 파라미터를 통해 알아보는 사회적 거리두기의 경제적 비용 비교 3탄 (0) | 2021.07.08 |
|---|---|
| 강화학습 파라미터를 통해 알아보는 사회적 거리두기의 경제적 비용 비교 2탄 (0) | 2021.07.07 |
| 고중량 벨트의 근골격계 보호 효과 분석 (0) | 2021.07.05 |
| 로드셀(Load Cell)의 데이터 처리가 느리다면 (HX711 사용기) (0) | 2021.07.03 |
| 로봇/기계분야 특허 읽는 법! (순서 파악하는 방법과 청구항 읽는 방법) (0) | 2021.07.02 |



